Очевидно, что в учете будут использоваться таблицы, а не схемы ER-моделей. Значит нам нужно перейти от Сущностей, Связей и Атрибутов к таблицам.
В теории реляционных баз данных существуют правила построения таблиц. Эти правила называются "нормализацией отношений" (здесь нормализация, как приведение к норме, нормальные, значит "построенные по правилам").
Если таблицы "не нормализованы" (не соответствуют правилам), то тогда в системе могут возникать ошибки. Эти ошибки называются "аномалиями". Различают аномалии "удаления", "добавления", "изменения".
Так как курс направлен на практическое применение, то теорию нормализации таблиц мы опустим. Вместо этого мы рассмотрим все возможные варианты Связей между Сущностями и для каждой связи выработаем свое правило перехода (см. таблицу ниже). Алгоритм перехода от ER-модели к таблицам будет следующий:
- берем готовую схему ER-модели и ищем в ней конкретную связь
- ищем подобную связь в таблице-шпаргалке (приведенной ниже)
- строим таблицы, как указано в шпаргалке.
Действуя данным способом, вы всегда создадите таблицы, которые удовлетворяют нормальным формам.
(!) В таблице синим цветом отображены вымышленные примеры, красным связи из СКВОЗНОГО ПРИМЕРА.
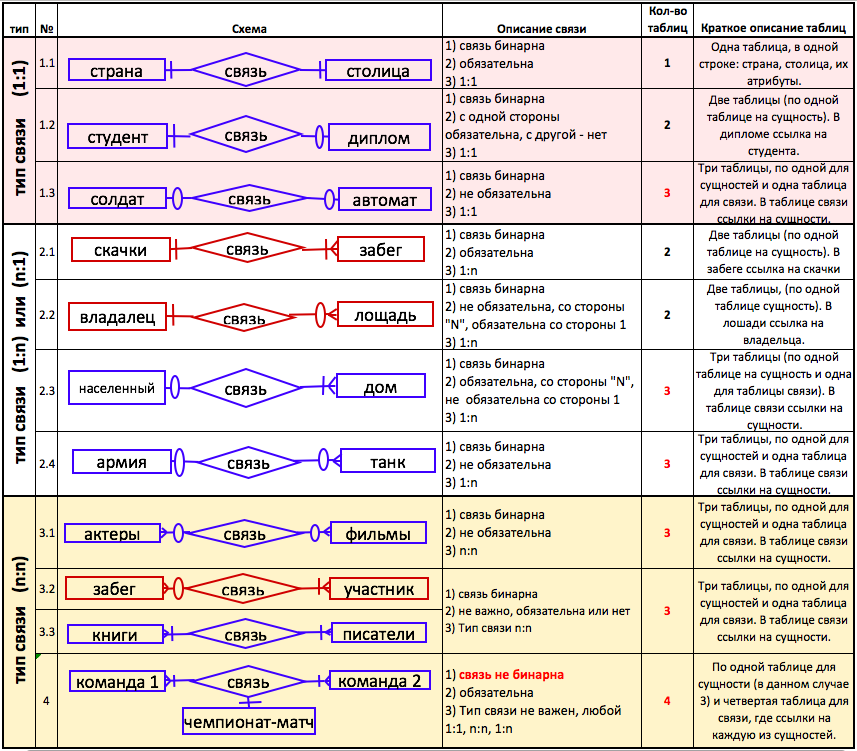
В таблице приведены все возможные варианты для бинарных связей и один пример для небинарных связей (для небинарных связей алгоритм применения типичный).
Перед тем, как перейти к детальному рассмотрению каждого случая связи, давайте рассмотрим общую схему потребности в таблицах, в зависимости от типа и кардинальности связи. Переход от типа связи (1:1) к → (n:n), и от (II) к → (00) увеличивает потребность в таблицах. См. рисунок ниже. Минимальная потребность для связи – 1 таблица, максимальная потребность – 3 таблицы. Для типа связи (n:n) и для кардинальности связи (00) всегда требуется 3 таблицы. См. рисунок ниже.
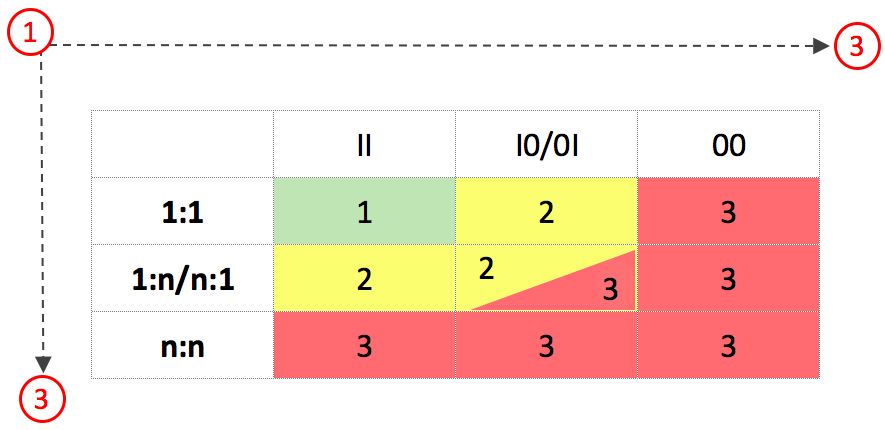
(!) Для небинарных связей требуется различное количество таблиц в зависимости от количества небинарных связей. Но для них существует правило: количество таблиц равно – количество Сущностей принимающих участие в связи, плюс одна таблица для Связи.
(!) Если вы готовы принять на веру то, что описано выше, и механически использовать "таблицу-шпаргалку", то можете переходить к главе 2.2 Знакомство с архитектурой A-techs.io. Все, нижеследующее до конца текущей главы – факультативно.
Подведем итоги главы: мы рассмотрели алгоритм перехода от ER-модели к макетам таблиц. Теперь можно приступить к реализации данных таблиц в учетной системе. С этой задачей решить будет проще, если иметь представление о архитектуре A-techs.io.
Рассмотрим подробно каждый пункт из таблица-шпаргалки.
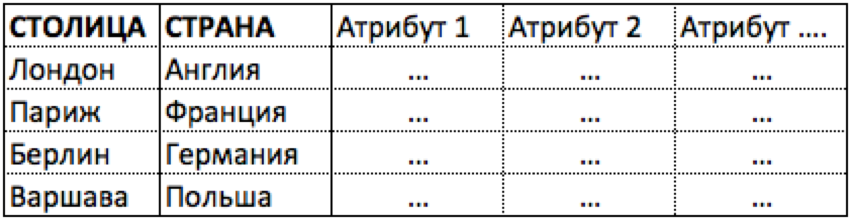
Пункт 1.1. Страна↔столица, (1:1), (II).
Это самый простой случай, когда для реализации связи требуется ВСЕГО одна таблица. Причина этого в том, что связь жестка и неделима. Берлин, всегда подразумевает Германию, а Франция всегда определяет Париж. Поэтому для хранения информации достаточно одной таблицы. В одной строке будет соответствующие столица и страна, а далее в одной строке будут все атрибуты страны или столицы. См. рисунок ниже.
Пункт 1.2. Студент↔диплом, (1:1), (I0).
У студента всегда одна дипломная работа, а у Диплома всегда один автор. Тип связи (1:1).
Кардинальность связи. Со стороны диплома связь кардинальна, у каждого диплома обязательно есть автор-студент. Со стороны студента некардинальна, есть студенты без диплома (не подошло время диплома, неоконченное высшее или отчисленные студенты), (I0). Теория говорит, что для реализации связи требуется две таблицы. Ключевой вопрос, который нас должен заинтересовать, почему теперь нам нужна не одна, а две таблицы (а это некое усложнение от варианта "все в одной таблице").
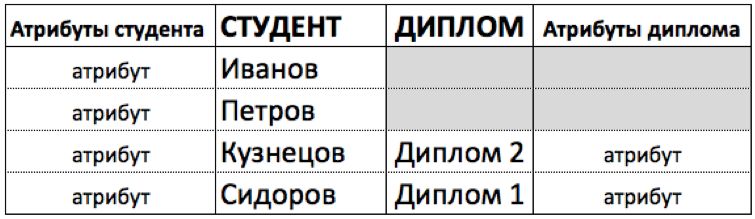
Ответ на это вопрос: так как не каждый Студент будет иметь Диплом, то строк в таблице Студент будет больше. Четыре строки в таблице Студенты и две строки в таблице для Дипломов, потому что у Иванова и Петрова нет дипломов. См. рисунок ниже.

Раз количество строк разное, то студентов хранить в таблице дипломов мы не сможем "физически". Для них там просто недостаточно строк (две, вместо необходимых четырех).
Возможно, что дипломы не поместить в таблицу студентов (там строк для диплома более, чем достаточно)”. Но тогда, если у какого-то Студента нет Диплома, то в этой строке все колонки для Атрибутов Диплома будут пустыми (эти поля закрашены серым). Это противоречит одному из правил, что все значения в таблицах должны быть заполнены. Поэтому теория говорит, что требуются две таблицы.
Существует еще одна причина, почему мы не можем поместить все данные в одну таблицу.
Если вы работали только с Excel, то сейчас вам понять это будет достаточно сложно. Дело в том, что когда вы работаете с Excel, то в нем нет отдельных Сущностей и Связей. В файле Excel вся информация - это лишь текст и адрес ячейки. Excel - можно представить, как файл Word, набор текста и цифр, который всего лишь умеет структурировать информацию в ячейки, но это все равно "мешанина" из букв, цифр и адресов ячеек, которые можно представить так, как изображено на рисунке ниже.
В такой архитектуре для Excel и Дипломы и Студенты - это просто текст с адресом ячейки. В информационной системе каждой Сущности будет выделено свое пространство. И оно будет организовано, наиболее удобно для поиска и работы с данной Сущностью. Например, можно будет искать Дипломы по темам или еще по каким-то параметрам. Если дипломы - это текстовое поле внутри таблицы Студенты, то получение информации усложняется.
Тогда а почему не три таблицы? Потому что в данному случае даже двух таблиц достаточно для любых манипуляций с данными. Возможно, что у была бы потребность еще в учете состава комиссии, кто принимал дипломную работу и тогда нам бы понадобились еще Сущности и двух таблиц бы не хватило, но в рамках задачи вот этой Связи - нам достаточно двух таблиц.
Тогда возникает вопрос, а почему в прошлом примере понадобилась лишь одна таблица? Потому что связь настолько жесткая и неделимая (1:1, II), что две сущности ведут себя как одно целое. Можно сказать, что Столица, это атрибут Страны. Или Страна – это атрибут Столицы. Или даже и Страна и Столица - это Атрибуты какой-то Сущности более высокого уровня. В данном случае из за того, что связь (1:1, I0) так сделать нельзя.
Пункт 1.3. Солдат↔автомат. (1:1), (00).
Считаем, что солдат связан с автоматом 1:1.
Но связь с обеих сторон не кардинальна, (00). У солдата может не быть автомата, (если он работает на кухне) и у автомата может не быть солдата (если он лежит на складе). Для реализации такой связи требуется уже три таблицы: отдельная таблица для автоматов, отдельная таблица для солдат, и еще одна таблица для связи. См. рисунок ниже.

(!) Внимание. Связь 1:1, как и в прошлых двух примерах, но теория требует уже не одной, и даже не двух, а трех таблиц! Почему? Рассмотрим это подробнее.
Раз связь необязательна, то количество строк (записей) в таблицах может быть разным. В такой модели солдаты “живут” сами по себе, автоматы “живут” сами по себе. Встречаются они в таблице “выдача оружия”. В таблице “выдача оружия” будут свои атрибуты (дата выдачи, например).
Попробуем поместить эти данные в одну таблицу вместо трех. Но в такой таблице у нас уже будет множество строк, в которых или солдаты или автоматы будут пустыми. См. рисунок ниже (пустые поля для наглядности выделены серым).
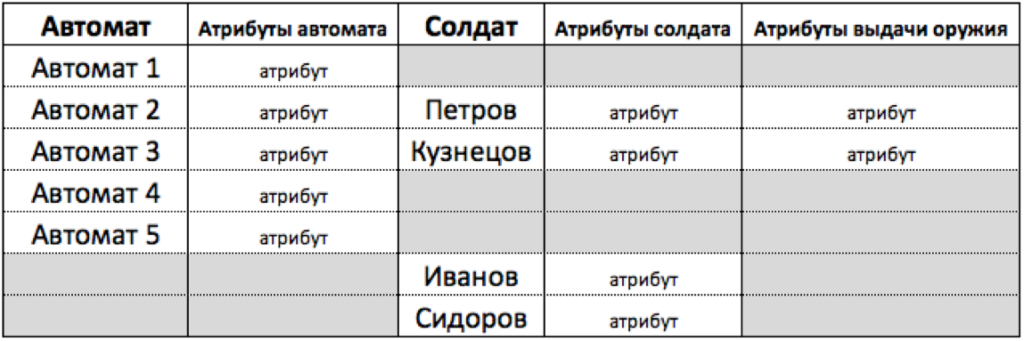
(!) Если отбросить правило, что все поля должны быть заполнены, то может показаться, что и в такой таблице можно вести учет. В таблице можно увидеть всех солдат и все автоматы. Можно отобрать всех солдат с оружием, можно все автоматы без солдат. И фильтры Excel и сводная таблица в Excel с этим справится.
Но на самом деле здесь есть еще одно ограничение, которое не позволяет поместить эти данные в одну таблицу. Это ограничение станет понятно на следующем уровне, на “уровне операций”. Если коротко, то строка должна записываться одновременно, когда пользователь отражает какое-то событие в системе. Например, появление автомата в учете - это операция “приход автомата на склад”. Появление солдата в учете - это операция “формирование подразделения” или “призыв граждан на военную службу”. Выдача автомата какому-то конкретному солдату - это будет третья операция. Эти операции будут делаться в системе разными сотрудниками и в разные моменты времени. И реализации этой связи в одной таблице станет потребует точечного дописывания в ячейки таблицы, работа с одними и теми же ячейками многих сотрудников, что сделает систему и работу с ней очень сложной. А как отчет - эта таблица имеет право на существование.
(!) На данном примере можно продемонстрировать аномалию удаления и добавления. Считаем, что поле "автомат", это ключ, главное поле в этом случае, пока нет выдачи автомата, то мы не можем внести солдата в систему. Это аномалия добавления. А при при утилизации автомата (и удаления автомата из таблицы) при удалении этой строки, вместе с автоматом будет удален и солдат.
Можно попробовать поместить данные в две таблицы, вместо трех. См. рисунок ниже (пустые поля для наглядности выделены серым).

В таком варианте реализации также не решена проблема "дописывания данных в отдельные ячейки" при наступлении различных событий.
Мы рассмотрели все связи типа 1:1. Переходим к типам связи (1:n).
Пункт 2.1. Забег↔скачки, (1:n), (II).
В скачках может быть много забегов, забег принадлежит одним скачкам (1:n).
Нет скачек без забега и не бывает забега без скачек. То есть связь обязательна в обе стороны (II).
Теория говорит, что хранения данных о такой связи требуются две таблицы. Первая таблица - таблица для Скачек (с атрибутами). Вторая таблица - таблица Забегов (со своими атрибутами). Связь реализуется, как ссылка на Скачки в таблице Забег. См. таблицу ниже.
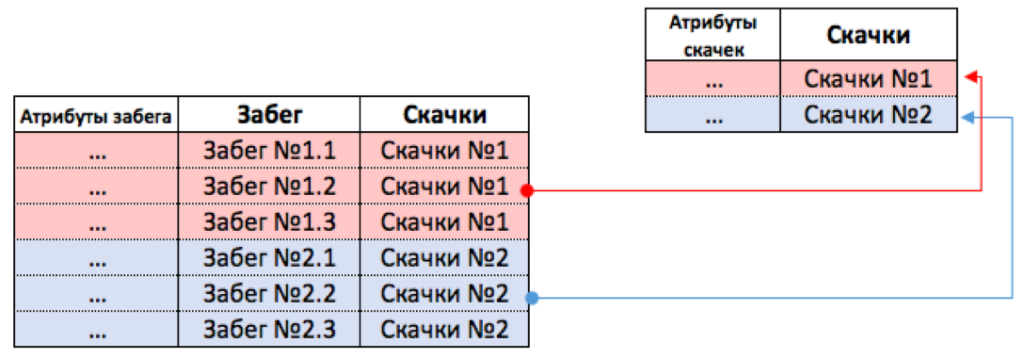
Давайте попробуем поместить все данные в одну таблицу.
В таблице Скачек меньше строк, поэтому туда нельзя будет поместить все Забеги, там буквально нет места для Забега (6 строк в таблице Забег и 2 строки в таблице Скачки). См. рисунок выше.
Хорошо, попробуем Скачки поместим в таблицу Забег? На первый взгляд проблем вообще нет. Даже нет пустых полей. См. рисунок ниже.
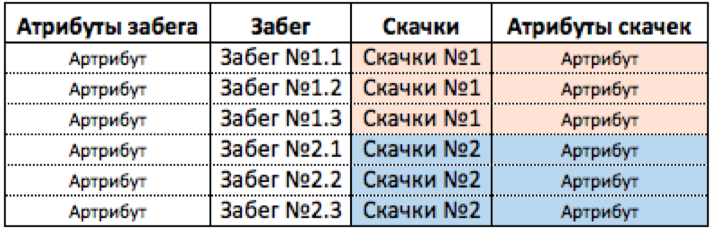
Такую таблицу сделать НЕЛЬЗЯ, из-за столбца (столбцов) Атрибуты скачек. Потому что в такой таблице данная информация будет дублироваться много раз. См. рисунок ниже.
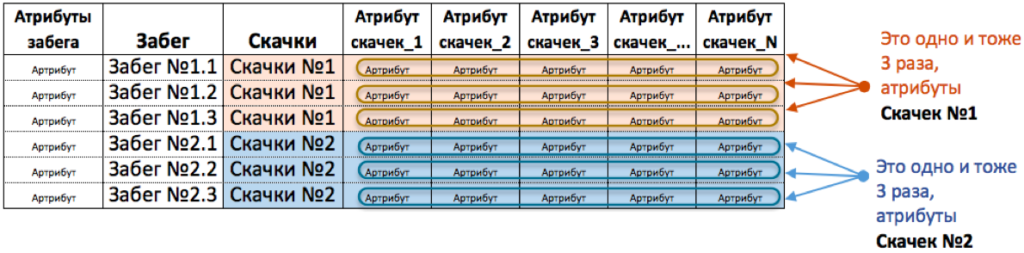
На первый взгляд, в этом нет проблемы, в excel достаточно ячеек, чтобы сохранить информацию. В более мощных информационных системах - тем более достаточно ресурсов. Но проблема здесь глубже. Предположим, что мы поместили все данные в одну такую таблицу.
Если в Скачках десять Забегов, то в "архитектуре одной таблицы" при заполнении Строки (или Формы), вам потребуется вносить одно и тоже, но уже 10 раз.
И в случае изменения какого-то Атрибута скачек, вам потребуется войти в КАЖДЫЙ забег и там изменить место проведения Скачек 10 раз. И не важно, Строка ли это в excel, или это Форма в информационной системе, вам потребуется переписывать одно и тоже 10 раз.
А если вы по ошибке исправили информацию в 9-ти Забегах, то возможна ситуация, когда через некоторое время вам потребуется какая-то информация о Скачках, то вы будете ломать голову, в какой Строке информация правильная, а в какой Строке - нет.
Конечно, можно попробовать решить такую задачу программно, то есть в случае изменения информации искать все строки с этими Скачками, но это огромная трата ресурсов разработчиков впустую и на практике так не делают.
(!) Это демонстрация аномалии изменения. Когда при изменении информации нам необходимо менять ее во многих местах, вместо одного.
(!) Несмотря на абсолютную очевидность, эта едва ли не основные идеи, как должны быть устроены таблицы, но выраженные “на пальцах”.
Идея в том, что когда мы пытаемся ошибочно поместить информацию в таблицу для нее НЕПРЕДНАЗНАЧЕННУЮ, то то мы можем сталкиваться со следующими проблемами:
1. в этой таблице может не хватать места (строк меньше, чем необходимо), и здесь возникают аномалии добавления и удаления.
2. в этой таблице избыток строк, и вам придется дублировать одну и туже информацию много раз. И здесь возникает аномалияизменения.
Пункт 2.2. Лошадь↔владелец, (1:n), (I0).
У владельца может быть много лошадей, у лошади один владелец (в нашей реальности нет “совладельцев”). То есть тип связи (1:n).
У лошади всегда есть владелец (связь обязательна), но у владельца может не быть лошадей (связь необязательна), например, старый владелец продал новому (I0). В этом случае для реализации связи нам потребуется две таблицы. ПО одной таблице для каждой сущности. В Сущности Лошади ссылка на Владельца. См. рисунок ниже.
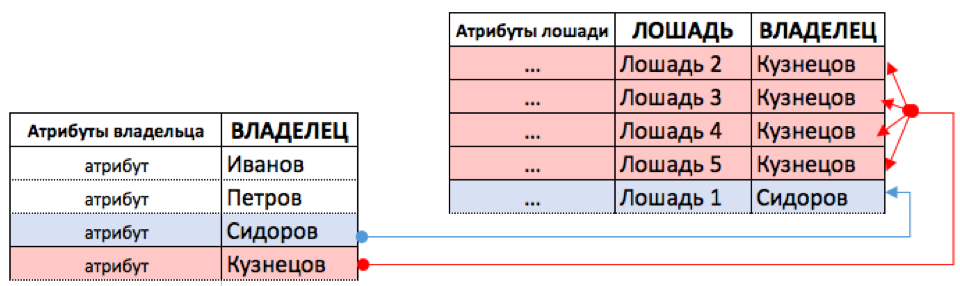
Давайте, как и в прошлом примере попытаемся поместить данные в одну таблицу. См. рисунок ниже.
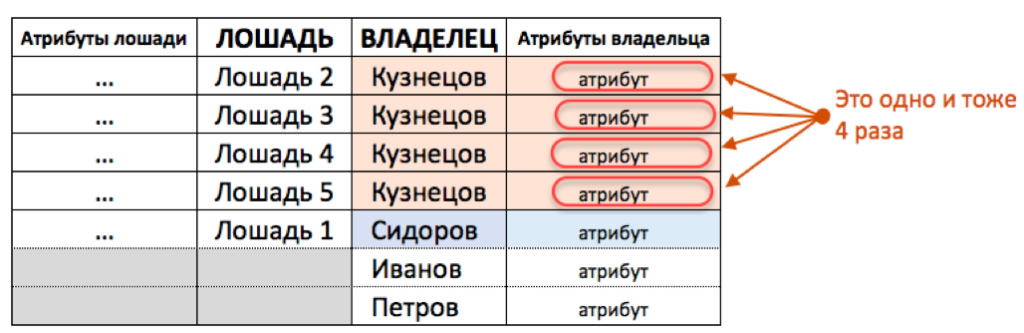
Если попытаться все поместить в одну таблицу, то часть полей будет пустыми (для тех Владельцев, у кого нет лошадей). И к тому же в случае внесения и изменения информации, как и в прошлом случае (со скачками и забегами) нам придется много раз переписывать атрибуты владельца, если владелец (как Кузнецов) имеет более, чем одну лошадь.
(!) В данном примере также будут возникать аномалии. Например, при изменении паспорта Кузнецова, потребуется изменять информацию много раз. А при изменении владельца Лошади 1, с Сидорова на другого владельца, информация о нем будет потеряна.
Пункт 2.3. Населенный пункт↔дом. Связь (1:n), (0I).
Тип связи. В населенном пункте много домов, дом принадлежит одному населенному пункту,(1:n).
Кардинальна связи. Населенный пункт обязательно имеет дома, но дом не обязательно принадлежит населенному пункту (например, скит староверов), (0I).
Связь реализуется в трех таблицах. Две таблицы для Сущностей и одна таблица для связи. См. рисунок ниже.

Причина потребности в трех таблицах в том, что таблице Населенных пунктов недостаточно строк, чтобы поместить в ней все Дома.
В таблице Домом мы не можем хранить ссылку на Населенный пункт, потому что не каждому дому соответствует Населенный пункт ( у скита нет населенного пункта). А также потому что нам придется редактировать по многу раз дублировать атрибуты населенных пунктов.
(!) Можете самостоятельно попробовать поместить данные в одну или две таблицы, вместо трех. И попробовать проанализировать какие аномалии (ошибки) будут возникать при добавлении, удалении или изменении данных.
Пункт 2.4 Армия↔танк. Связь (1:n), (00).
Армия может иметь много танков, но танк может принадлежать только одной армии. При этом армия армия может не иметь танков, и танк может быть без армии (в музее, например). Такая связь реализуется в трех таблицах.
Связь реализуется в трех таблицах. Две таблицы для Сущностей и одна таблица для связи. См. рисунок ниже.

(!) Можете самостоятельно попробовать поместить данные в одну или две таблицы, вместо трех. И попробовать проанализировать какие аномалии (ошибки) будут возникать при добавлении, удалении или изменении данных.
Пункт 3.1 Актеры↔фильмы. Связь (n:n), (00).
Каждый актер может сняться в большом количестве фильмов, и в фильме играет большое количество актеров. Тип связи (n:n).
Кардинальность связи. Но если считать актером того, кто получил театральное образование, то актер может не сняться ни в одном из фильмов. И некоторые фильмы могут не иметь актеров (документальные фильмы про природу, например). Кардинальность связи (00).
Связь реализуется в трех таблицах. Две таблицы для Сущностей и одна таблица для связи. См. рисунок ниже.

(!) Можете самостоятельно попробовать поместить данные в одну или две таблицы, вместо трех. И попробовать проанализировать какие аномалии (ошибки) будут возникать при добавлении, удалении или изменении данных.
Пункт 3.2 Забег↔участник. Связь (n:n), (0I).
В Забеге много Участников, и Участник может принимать участие во многих Забегах. Тип связи (n:n).
Кардинальность связи. Связь обязательна только с одной стороны. В забеге всегда есть участники, но участник может не участвовать в забеге. Кардинальность связи (0I).
Связь реализуется в трех таблицах. Две таблицы для Сущностей и одна таблица для связи. См. рисунок ниже.
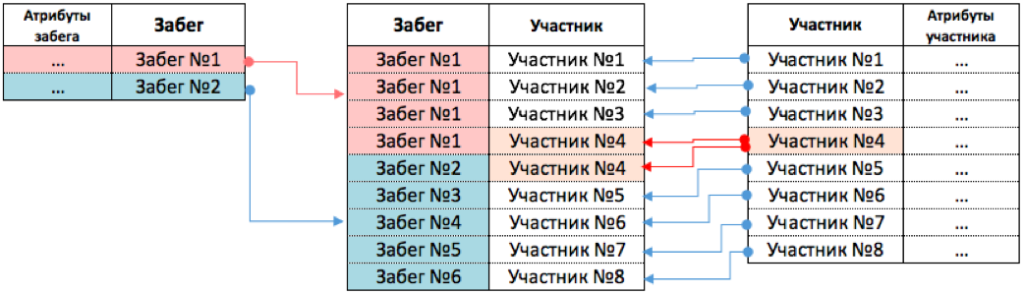
(!) Можете самостоятельно попробовать поместить данные в одну или две таблицы, вместо трех. И попробовать проанализировать какие аномалии (ошибки) будут возникать при добавлении, удалении или изменении данных.
Пункт 3.3 Книги↔писатели. Связь (n:n), (II).
Писатель может написать множество книг, и одну книгу могут писать два и более писателя (в соавторстве). Тип связи (n:n)
Кардинальность связи. Связь обязательна с обеих сторон. У книги всегда есть автор, и писатель всегда имеет хотя бы одну книгу (без этого он не писатель). Кардинальность связи (II).
Связь многие-ко-многим всегда реализовывается тремя таблицами. См. рисунок ниже. В одной таблице книги, в другой писатели и в третьей таблице они встречаются.

(!) Можете самостоятельно попробовать поместить данные в одну или две таблицы, вместо трех. И попробовать проанализировать какие аномалии (ошибки) будут возникать при добавлении, удалении или изменении данных.
Пункт 4. Команда↔команда↔матч. Не бинарная связь (n:1:n), (II).
(!)Не бинарная связь используется тогда, когда без ее использования теряется логический смысл связи. Мы уже рассматривали пример игр в футбольных чемпионатах. Команды в ходе своего существования и даже в ходе игр одного чемпионата могут встречаться с друг другом много раз, и каждый раз это будут разные матчи.
То есть в примере с футбольными играми смысл будет иметь только одновременная “связка”: команд, чемпионата и игры.
В небинарных связях нужно использовать столько таблиц, сколько участвует сущностей, и плюс одну таблицу для связи. См. рисунок ниже.
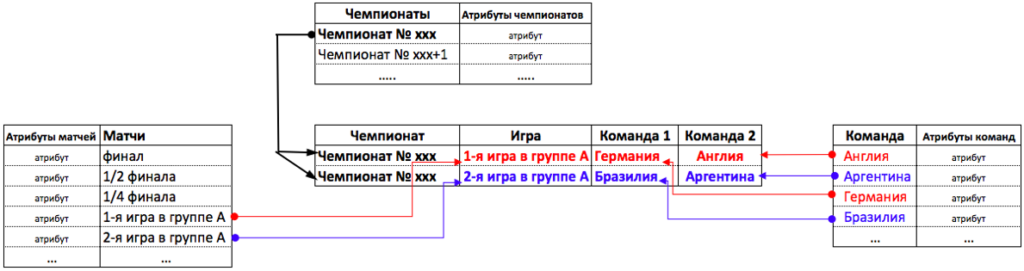
(!) Можете самостоятельно попробовать поместить данные в одну или две таблицы, вместо трех. И попробовать проанализировать какие аномалии (ошибки) будут возникать при добавлении, удалении или изменении данных.